Dokumenten-Archievierung mit dem Brother ADS4300N
Nachdem ich mir alle möglichen Scanner lange angeschaut und im Artikel URL bewertet habe, habe ich mich aufgrund eines sehr guten Angebots bei Amazon Warehouse für den ADS4300N entschieden. Er ist nicht der schnellste und hat „nur“ 100MBit/e Ethernet, aber für meine Belange ist er völlig Ausreichend und hat jetzt als Dokumentscanner im Regal einen gut erreichbaren Platz gefunden.
Nachdem Aufbau des Scanners habe ich mir Gedanken um die Prozeßkette gemacht.

Mein Zielbild ist dabei möglichst wenig manuell machen zu müssen (orange) und so viel wie möglich automatisiert (grün) abarbeiten zu lassen.
Anschließend habe ich mich in den VSFTPD auf Ubuntu eingelesen und für die Verarbeitung auf dem Server einen User Namens „consume“ erzeugt. Ich habe mir gedacht, dass ich vom Scanner aus auf einen Knopf drücke und dann die Dokumente auf den Ubuntu Server mittels FTP übertrage. Ich wollte dem Scanner dabei nicht den Zugriff auf root geben. Auf dem Server wiederum landen die Dokumente dann unter /home/consume. Hier für ist wie gesamt auf dem Server ein User consume notwendig, der Bequemlichkeit halber habe ich dem user consume auch als Passwort consume gegeben, steht alles ja bei mir zu Hause herum und ist isoliert von der Welt.
User auf dem Server anlegen in der Bash:
sudo useradd -m consome
sudo passwd consume
New password: consume
Retype new password: consume
passwd: password updated successfullyAnschließend habe ich den nicht ganz so eingängigen VSFTPD installiert.
VSFTPD Server installieren per Bash:
sudo apt-get install vsftpd
sudo systemctl start vsftpd
sudo systemctl enable vsftpd
sudo systemctl status vsftpd
sudo nano /etc/vsftpd.conf
Die Konfiguration habe ich mit einem anderen Linux Rechner so lange ausgedadellt, bis ich mich mit User consume anmelden und Files hochladen konnte. Dieser Teil hat eine ganze Menge Zeit konsumiert, da der VSFTPD nicht so leicht zu verstehen ist. Ich habe die VSFTPD Version 3.0.5-0ubuntu1 am Start.
Modifizieren der VSFTPD Config in der Bash mit Nano:
apt-cache show vsftpd
Package: vsftpd
Architecture: amd64
Version: 3.0.5-0ubuntu1
Priority: extra
Section: net
Origin: Ubuntu
Hier ist meine Konfiguration, die mit dem VSFTPD Version 3.0.5-0ubuntu1 problemlos funktioniert.
# VSFTPD.conf für Brother ADS4300N mit FTP Übertragung
listen=NO
listen_ipv6=YES
anonymous_enable=NO
local_enable=YES
write_enable=YES
local_umask=022
dirmessage_enable=YES
use_localtime=YES
xferlog_enable=YES
connect_from_port_20=YES
xferlog_file=/var/log/vsftpd.log
xferlog_std_format=YES
secure_chroot_dir=/var/run/vsftpd/empty
pam_service_name=vsftpd
rsa_cert_file=/etc/ssl/certs/ssl-cert-snakeoil.pem
rsa_private_key_file=/etc/ssl/private/ssl-cert-snakeoil.key
ssl_enable=NO
Nachdem der FTP Server erfolgreich getestet und geprüft war, habe ich mich um den Brother ADS4300N Scanner gekümmert. Da ich selber kein Windows-User bin, musste die Konfiguration über das WebInterface des Scanners erfolgen. Zu erst also auf der Fritzbox die IPv4- oder IPv6-Adresse des Scanners herausfinden, das Geräte für Aussen-Zugriffe aus und auf das Internet sperren, sowie danach auf das Webinterface per Browser zugreifen. Als alter Verfechter der IPv6-Welt also dann Zugriff auf https://[fda0:d594:f020:ffff:20e:c6ff:fe92:6621]. Nach einiger Recherche hab ich herausgefunden, dass zuerst die Zuweisung des Protokolls zu einem Profil erfolgen muss, dadurch ändern sich dann für Schritt zwei die innerhalb des Profils möglichen Einstellungswerte und zuletzt kann man dieses Profil dann einer der Drei Scanner-Knöpfe auf dem Gerät zuweisen.
Genug der Vorrede geben wir also für Profil #1 die Nutzung von FTP vor. (Wer ein anderes Transferprotokoll verwenden möchte kann sich hier natürlich gerne anders entscheiden.)
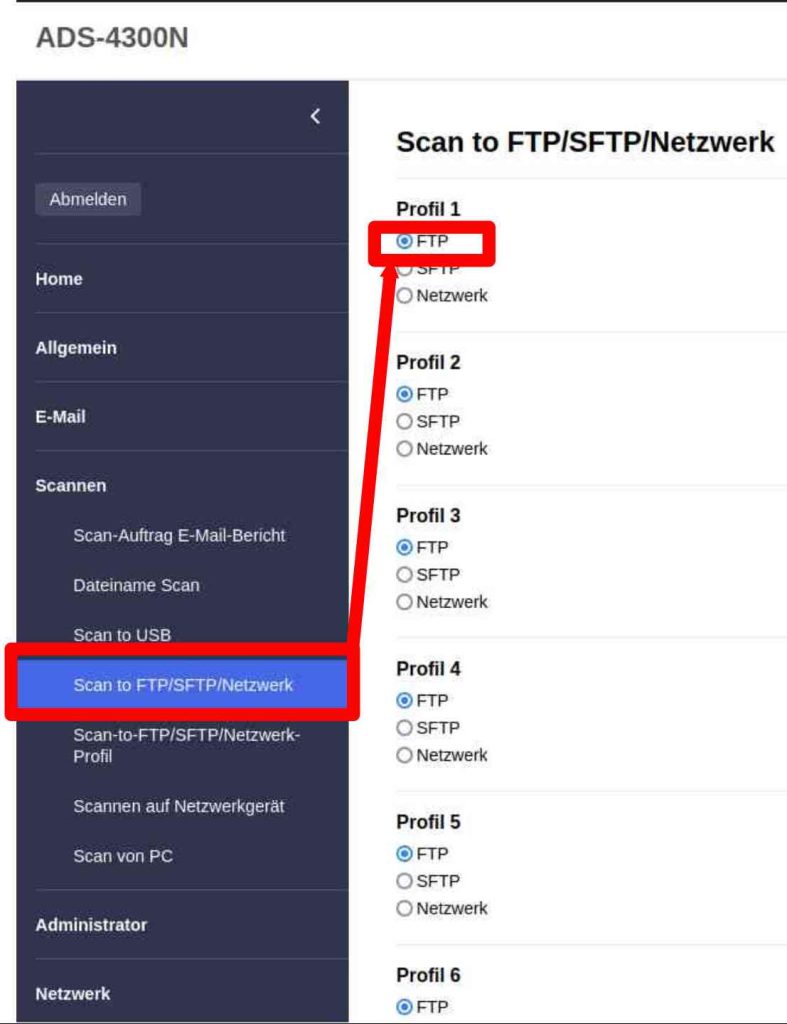
Als nächstes gehen wir in die Profilauswahl und suchen uns Profil #1 durch anklicken aus.
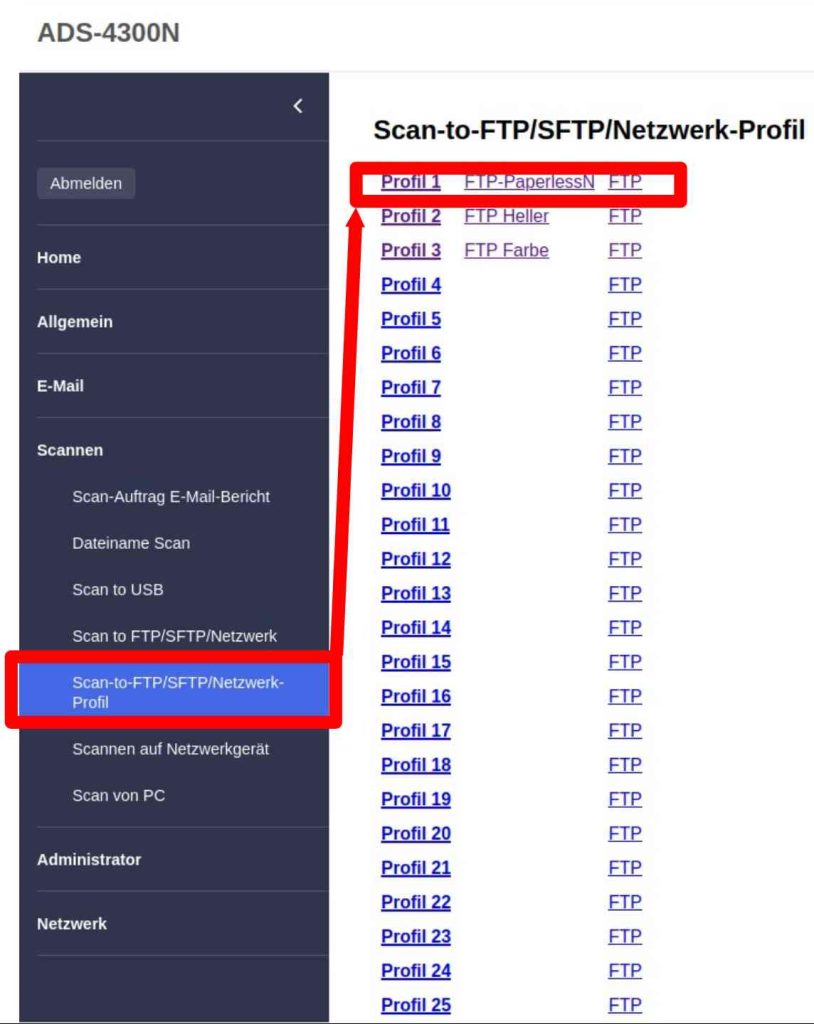
Innerhalb von Profil #1 können die entsprechenden Felder für den Datentransfer zum Server mittels FTP konfiguriert werden, die in meinem Falle leider nur für IPv4 einstellbar sind 🙁 aber was soll es. Durch offenlassen des Zielordners wird auf dem Server automatisch der Home Ordner des UsersConsum genommen, also /home/consume.
m h dom mon dow command
*/5 * * * * /root/scanmover.sh
Soweit so gut, jetzt ist muss dieses Profil#1 mit dem Namen „FTP-PaperlessN“ noch auf einen Knopf gelegt werden. Das geschieht im letzten Schritt.
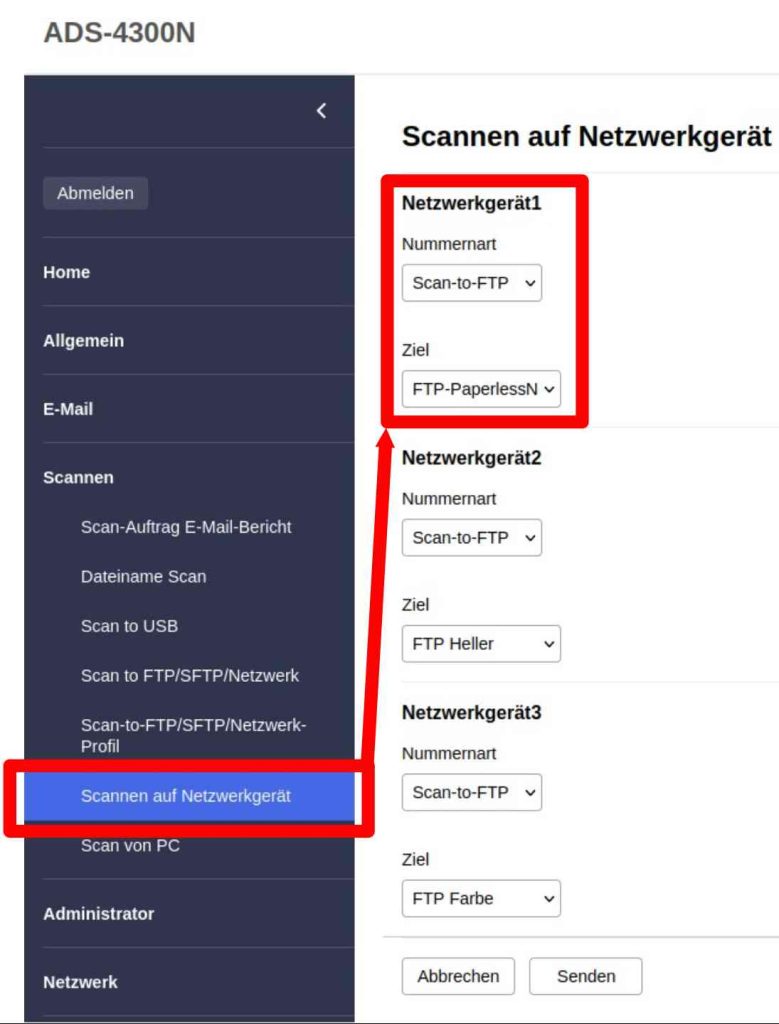
Hier hätte man an Stelle von Netzgerät1 auf ruhig mal von einem Knopf in der Anleitung und dem WebInterface sprechen können, aber naja – mit entsprechendem herum Probieren bin ich dann drauf gekommen, was gemeint ist.
Ein erster kurzer Test zeigt mir, dass das nach drücken von Knopf #1 gecannte Dokument mittels FTP erfolgreich auf den Paperless-NGX Server übertragen wird. Da landet es wie gewünscht in /home/consume. der Paperless-NGX weiß davon natürlich nichts und nun fehlt und noch der Prozessierungs-Schrit auf dem Server, um die Dokumente (welche nach dem Scan User:consume und der Gruppe:users gehören) so zu modifizieren, dass sie User:paperless und der Gruppe:paperless gehören und in das Consume-Verzeichnis zu verschieben. Da das ganze am Ende ja automatische passieren soll und keine zeitkritischen Aspekte beim Scannen zu beachten sind, habe ich mich für ein bash-Script das erst prüft, ob Dokumente im Quell-Ordner liegen und dann die Veränderungen durchführt, wobei anschließend das Verschieben ausführt. Mein Script „scanmover.sh“ ist jetzt keine Schönheit, erfüllt aber seinen Zweck.
#!/bin/bash
if [ ! -f /home/consume/ADS* ]
then
echo "no files in consome-home ordner"
else
echo "Files in consume-home Ordner"
chown paperless:paperless /home/consume/ADS*
mv /home/consume/ADS* /opt/paperless-ngx/consume/
exit 0
fi
Wichtig ist dabei, dass das Script ausführbar ist, also sudo chmod 700 scanmover.sh und es anschließend durch Root-CRON als Job alle 5 Minuten (reichen mir persönlich als Frequenz aus) zu starten. Also in der Bash:
sudo crontab -e
# Scanmover alle 5 Minuten starten
*/5 * * * * /root/scanmover.sh
Was soll ich sagen, alle 5 Minuten werden die Dokumente in das Consume-Verzeichnis von Paperless-NGX geholt und anschließend dann nach dem Import über Tika und Gotenberg in der Inbox von paperless-NGX angzeigt, wo ich diese dann von Hand prüfe, ob der entsprechende Korrespondent und die Tags stimmen. Leider geht bei diesem Prozeß jedes Dokument, welche im Querformat vorliegt in die Hose, da kein automatisches Ausrichten der Dokumente ausgeführt wird. Allerdings liegen ja die Dokumente im überwiegenden Teil, also Rechnung, Verträge, Anleitungen, Dokus, Briefe, etc., im Hochformat vor.


Neueste Kommentare